隨著電子商務的蓬勃發展和數據量的爆炸式增長,如何從海量數據中挖掘用戶偏好、實現精準的商品推薦,并直觀地展示分析結果,已成為提升平臺競爭力的核心。Python,憑借其豐富的數據科學生態系統,成為開發此類系統的理想選擇。本項目旨在構建一個集大數據商品推薦與可視化分析統計于一體的綜合系統(代號:2twx0),以賦能商業決策與優化用戶體驗。
一、 系統核心架構
系統整體采用模塊化、分層設計理念,確保可擴展性與可維護性,主要分為三大核心模塊:
- 數據層:負責數據的采集、存儲與預處理。系統整合來自用戶行為日志(點擊、瀏覽、購買、收藏)、商品屬性信息、用戶畫像等多源異構數據。利用Python的
Pandas、NumPy進行數據清洗、轉換與特征工程,并使用SQLAlchemy或直接連接HDFS、HBase(針對超大規模數據)或MySQL/PostgreSQL(針對結構化數據)進行數據存儲與管理。
- 算法與推薦引擎層:這是系統的“大腦”。基于處理后的數據,實現多種推薦算法:
- 協同過濾:包括基于用戶的協同過濾(User-CF)和基于物品的協同過濾(Item-CF),使用
scikit-surprise或TensorFlow/PyTorch實現。
- 內容推薦:利用商品標簽、描述文本(通過
Jieba分詞、TF-IDF或詞嵌入)計算相似度。
- 混合推薦:融合協同過濾、內容推薦以及基于深度學習的模型(如Wide & Deep、Neural CF),以提升推薦的準確性和多樣性。該層通過
Flask或FastAPI框架封裝為RESTful API服務,供上層應用調用。
- 可視化與分析展示層:這是系統的“儀表盤”。利用強大的Python可視化庫,將數據洞察和推薦效果以直觀圖表形式呈現:
- 用戶交互界面:可考慮使用
Streamlit、Dash或Gradio快速構建交互式Web應用,降低開發門檻。
- 統計圖表:使用
Matplotlib、Seaborn繪制用戶活躍度趨勢、商品銷量排行、品類分布等統計圖表。
- 高級可視化:使用
Plotly、PyEcharts創建可交互的熱力圖(展示用戶-商品關聯)、關系網絡圖(展示商品關聯規則)、地理信息圖等。
- 推薦結果解釋:可視化展示推薦給特定用戶的商品列表,并可關聯顯示推薦理由(如“因為您購買過X”、“與您喜好相似的用戶也喜歡”)。
二、 關鍵技術實現
- 大數據處理:對于實時性要求高的場景,可以集成
Spark(通過PySpark)進行分布式實時計算;對于批處理任務,可使用Apache Airflow進行工作流調度。 - 模型訓練與更新:推薦模型需要定期(如每日)使用新數據重新訓練以保持時效性。此過程可自動化,并將新模型部署到推薦引擎。
- 系統性能:引入緩存機制(如
Redis)存儲熱門推薦結果和用戶會話數據,以大幅降低數據庫壓力和API響應延遲。 - 評估與優化:通過A/B測試框架,對比不同推薦策略的效果。關鍵評估指標包括點擊率(CTR)、轉化率、準確率、召回率、覆蓋率等,這些指標同樣應在可視化面板中動態展示。
三、 可視化分析統計功能詳述
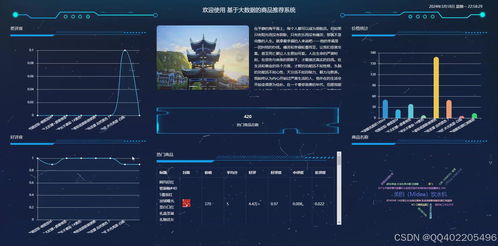
系統可視化面板(2twx0)應包含但不限于以下儀表板:
- 全局概覽儀表板:展示核心KPI,如當日總訪問量、訂單數、推薦點擊率、GMV等。
- 用戶行為分析板:分析用戶生命周期、新老用戶占比、活躍時段熱力圖、用戶流失預警。
- 商品分析板:展示商品銷量/瀏覽量的Top N排行、商品品類銷售漏斗、庫存與銷售關聯分析。
- 推薦效果分析板:這是系統的特色,可視化展示不同推薦算法的實時效果對比、推薦商品的曝光-點擊-轉化漏斗、長尾商品覆蓋率變化等。
- 個性化查詢面板:允許運營人員輸入特定用戶ID或商品ID,查看該用戶的個性化推薦列表及其生成路徑,或查看某商品的關聯推薦網絡。
四、 開發與部署
采用敏捷開發模式,使用Git進行版本控制。環境依賴通過conda或pipenv管理。最終系統可通過Docker容器化,并使用Nginx + Gunicorn部署Web服務,實現高并發訪問。整個數據處理與模型訓練流水線可部署在云服務器或大數據平臺上。
五、
本“基于大數據的商品推薦與可視化分析統計系統”利用Python的全棧數據科學能力,構建了一個從底層數據處理、智能算法推薦到頂層可視化交互的完整閉環。它不僅能夠通過精準推薦提升用戶滿意度和商業收益,更能通過強大的可視化分析功能,將數據轉化為直觀洞察,為商品運營、市場營銷和戰略決策提供強有力的數據支撐。系統代號2twx0寓意著通過技術與數據(2進制、twist交織、visualization可視化、analytics分析)實現商業價值的無限(0為循環)探索。